Linux抓取网页方式(curl+wget)
Linux抓取网页,简单方法是直接通过 curl 或 wget 两种命令。
curl 和 wget 命令,目前已经支持Linux和Windows平台,后续将介绍。
curl 和 wget支持协议
curl 支持 http,https,ftp,ftps,scp,telnet等网络协议,详见手册 man curl
wget支持 http,https,ftp网络协议,详见手册man wget
curl 和 wget下载
1、Ubuntu平台
wget 命令安装:
sudo apt-get install wget(普通用户登录,需输入密码; root账户登录,无需输入密码)
curl 命令安装:
sudo apt-get install curl(同 wget)
2、Windows平台
wget 下载地址:wget for Windows
curl 下载地址:curl Download
wget 和 curl 打包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后,直接是curl.exe格式,拷贝到系统命令目录下
C:\Windows\System32
即可
Windows平台下,wget下载解压后,是wget-1.11.4-1-setup.exe格式,需要安装;安装后,在环境变量 - 系统变量 - Path 中添加其安装目录即可
curl 和 wget 抓取实例
抓取网页,主要有url 网址和proxy代理两种方式,下面以抓取“百度”首页为例,分别介绍
1、 url 网址方式抓取
1)curl下载百度首页内容,保存在baidu_html文件中
curl http://www.baidu.com/ -o baidu_html
2)wget下载百度首页内容,保存在baidu_html文件中
wget http://www.baidu.com/ -O baidu_html2
有的时候,由于网速/数据丢包/服务器宕机/等原因,导致暂时无法成功下载网页
这时,可能就需要多次尝试发送连接,请求服务器的响应;如果多次仍无响应,则可以确认服务器出问题了
1)curl多次尝试连接
curl --retry 10 --retry-delay 60 --retry-max-time 60 http://www.baidu.com/ -o baidu_html
注: --retry表示重试次数; --retry-delay表示两次重试之间的时间间隔(秒为单位); --retry-max-time表示在此最大时间内只容许重试一次(一般与--retry-delay相同)
2)wget多次尝试连接
wget -t 10 -w 60 -T 30 http://www.baidu.com/ -O baidu_html2
注:-t(--tries)表示重试次数; -w表示两次重试之间的时间间隔(秒为单位); -T表示连接超时时间,如果超时则连接不成功,继续尝试下一次连接
附:
curl 判断服务器是否响应,还可以通过一段时间内下载获取的字节量来间接判断,命令格式如下:
curl -y 60 -Y 1 -m 60 http://www.baidu.com/ -o baidu_html
注:-y表示测试网速的时间; -Y表示-y这段时间下载的字节量(byte为单位); -m表示容许请求连接的最大时间,超过则连接自动断掉放弃连接
2、 proxy代理方式抓取
proxy代理下载,是通过连接一台中间服务器间接下载url网页的过程,不是url直接连接网站服务器下载
两个著名的免费代理网站:
freeproxylists.net(全球数十个国家的免费代理,每日都更新)
xroxy.com(通过设置端口类型、代理类型、国家名称进行筛选)
在freeproxylists.net网站,选择一台中国的免费代理服务器为例,来介绍proxy代理抓取网页:
218.107.21.252:8080(ip为218.107.21.252;port为8080,中间以冒号“:”隔开,组成一个套接字)
1)curl 通过代理抓取百度首页
curl -x 218.107.21.252:8080 -o aaaaa http://www.baidu.com(port 常见有80,8080,8086,8888,3128等,默认为80)
注:-x表示代理服务器(ip:port),即curl先连接到代理服务器 218.107.21.252:8080,然后再通过218.107.21.252:8080下载百度首页,最后 218.107.21.252:8080 把下载的百度首页传给curl至本地(curl不是直接连接百度服务器下载首页的,而是通过一个中介代理来完成)
2)wget 通过代理抓取百度首页
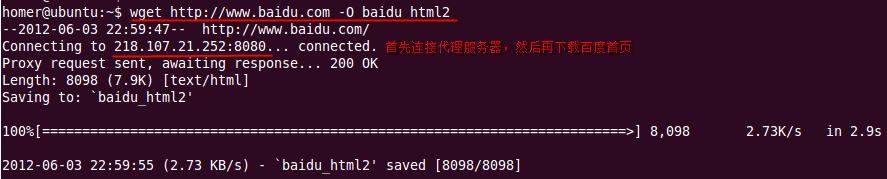
wget通过代理下载,跟curl不太一样,需要首先设置代理服务器的http_proxy=ip:port
以ubuntu为例,在当前用户目录(cd ~),新建一个wget配置文件(.wgetrc),输入代理配置:
http_proxy=218.107.21.252:8080
然后再输入wget抓取网页的命令:
wget http://www.baidu.com -O baidu_html2
代理下载截图:
抓取的百度首页数据(截图):
其它命令参数用法,同url网址方式,在此不再赘述
ftp协议、迭代子目录等更多的curl 和 wget用法,可以man查看帮助手册
知识拓展:
在国内,由于某种原因一般难以直接访问国外某些敏感网站,需要通过 WBM 或 代理服务器才能访问
如果校园网和教育网有IPv6,则可以通过sixxs.org免费代理访问facebook、twitter、六维空间等网站
其实,除了WBM 和 IPv6+sixxs.org代理方式外,普通用户还是有其它途径访问到国外网站
下面介绍两个著名的免费代理网站:
freeproxylists.net(全球数十个国家的免费代理,每日都更新)
xroxy.com(通过设置端口类型、代理类型、国家名称进行筛选)
curl 项目实例
使用curl + freeproxylists.net免费代理,实现了全球12国家google play游戏排名的网页抓取以及趋势图查询(抓取网页模块全部使用Shell编写,核心代码约1000行)
游戏排名趋势图请见我先前的博客:JFreeChart项目实例
版权所有: 本文系米扑博客原创、转载、摘录,或修订后发表,最后更新于 2018-10-14 20:41:34
侵权处理: 本个人博客,不盈利,若侵犯了您的作品权,请联系博主删除,莫恶意,索钱财,感谢!